
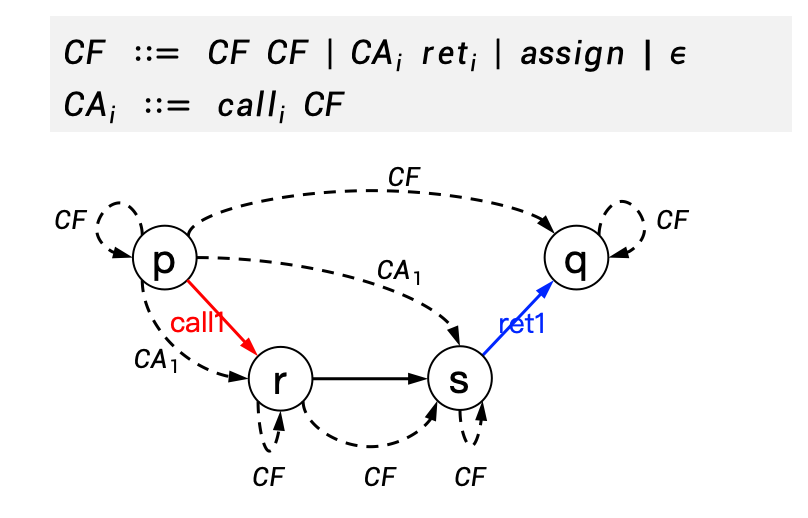
CFL-reachability与Graspan
CFL-reachability
在图分析里,我们经常会遇到“能否从某个点走到另一个点”的问题,这就是可达性问题。如果路径必须满足某些约束(例如成对匹配的调用/返回),那就不是普通的图可达性,而是更复杂的带语言约束的可达性。
CFL-reachability就是在图上寻找一条路径,使得这条路径上的边标签序列属于某个上下文无关语言 (Context-Free Language, CFL)。
上下文无关文法
文法是用来 描述语言(字符串集合) 的一种规则系统。

例如,这个文法:
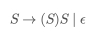
可以推出如下字符串:””, “()”, “()()”, “(())”, “(()())”, …
简单来说,核心思想是为图上的路径赋予“语法”或“语义”。不是任意路径都表示一个有效的信息流,只有那些符合特定“语法规则”的路径才有效。这个“语法规则”就是上下文无关文法。这样一来,图上从点u到点v的可达性问题,就变成了:是否存在一条从u到v的路径,其路径上的标签序列能够由给定的上下文无关文法生成。
把静态分析问题转化成图的可达性问题
为什么可以把程序分析问题转化成CFL-reachability问题?
在静态分析中,我们经常关心一些程序元素之间的关系,例如:
- 指针分析:某个指针p 可能指向哪些对象?
- 数据流分析:某个变量的值可能来自哪些定义?
- 安全检查:某个资源是否被正确使用?
这些问题本质上都涉及到:“能不能从某个程序点(或变量、对象)到达另一个程序点?”
CFL-reachability如何把静态分析问题转化成图的可达性问题?
我们需要根据分析的目标,将程序代码建模成一个图(通常是有向图),并为图的边赋予特定的标签。
- 节点(Vertices):可能代表程序中的程序变量、内存对象、表达式、调用点等等。
- 边(Edges):代表节点之间的关系或操作,如赋值、运算、参数传递等等。每条边都有一个标签(Label),这个标签来自于一个有限的字母表。
这样,程序分析就变成了图上的路径可达性问题。
例子——指针分析
以不考虑程序中控制流的指针分析为例:分析哪些指针变量可能指向哪些堆对象。在图模型中,这变成了一个可达性问题。
节点:程序里的表达式(如变量 a, b, &c)。
边:值的流动,分三类:
- A-edge (Assignment):赋值语句 a = b 建立A边 b → a。
- D-edge (Dereference):对于解引用a,建立边 a → a;类似的,对于取值表达式&a,可以建立边&a → a。
- M-edge (Malloc/Alloc):对于内存分配操作a = malloc( ) 建立从特殊节点Alloc → a的M边。
这样,程序就被转化为一张表达式图,表示指针值在程序中的传播。
如果某个分配点(malloc 对象)能通过图中一条满足规则的路径到达变量节点,那么该变量就可能指向该对象。
单纯的“路径可达”还不够,因为指针分析要保证某些操作(取址、解引用)的匹配性。这里用到上下文无关文法 (CFG) 来描述合法路径模式。
对象流 (Object Flow):OF ::= M VF
值流(Value Flow):VF ::= (A MA?)*
要使变量v指向对象o(即malloc分配的内存),在表达式图中必须存在一条从o到v的OF路径。OF的定义:它必须以一条分配(M)边开始,后跟一条将对象地址传播到变量的VF路径。VF路径可以是一系列简单赋值(A)边的序列,也可以是赋值边与MA(内存别名)路径的结合。
当两个左值表达式可能指向相同的内存位置时,它们构成内存别名;而当这两个表达式可能计算出相同值时,则构成值别名。
内存别名 (Memory Alias):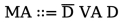
每条边都有一个带”横线”标签的逆向边。例如,对于每条边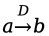 ,会自动存在边
,会自动存在边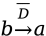 。
。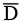 表示解引用的逆向操作,本质上等同于取地址操作。若(1)获取变量a的地址并写入变量b,(2)b是另一个变量c的值别名,(3)对c执行解引用操作,其结果与a中的值相同。
表示解引用的逆向操作,本质上等同于取地址操作。若(1)获取变量a的地址并写入变量b,(2)b是另一个变量c的值别名,(3)对c执行解引用操作,其结果与a中的值相同。
值别名(Value Alias):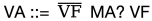
若(1)变量a与b互为内存别名,且(2)通过两条VF路径将a和b的值分别传播至另外两个变量c和d,则c和d包含相同的指针值。
如上,就将指针分析问题转化为了图可达性问题。
经典CFL-reachability算法

标准算法维护一个工作列表W来存储待处理的新边。在可达性求解过程中,算法迭代地从W中弹出一个项,遍历与项相邻的边,并根据文法将新生成的边加入图和工作列表。
Graspan
Graspan专门为跨过程静态分析(尤其是 CFL-reachability)设计。
1.单机磁盘支持:可以在普通开发者机器上运行,不依赖集群。图太大放不下内存时,可启用外存支持机制。
2.并行边对(Edge-Pair) 计算模型:每次迭代加载两个分区,在边对之间做合并,批量生成新边。并行化:不同顶点的边表可以在多个线程中独立处理。内置在线去重和快速合并算法,避免重复边导致的无终止或性能退化。
Preprocessing
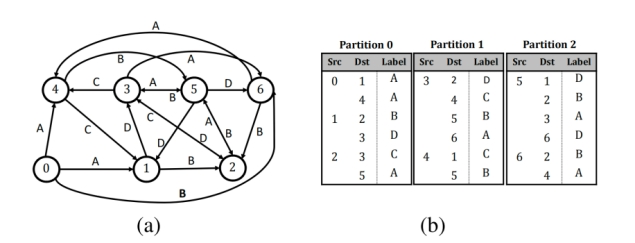
将顶点划分为逻辑区间(interval),每个区间定义一个分区,分区包含所有源点属于该区间的边。
分区内部,边按源点和目标点排序(按照边的源顶点ID进行排序,具有相同源顶点的边会被连续存储,并按照其靶区顶点ID排序。
图(a)展示了一个简单的有向图示例。假设Graspan将其顶点划分为三个区间0-2、3-4和5-6,图(b)则展示了对应的分区布局结构,这样可以实现快速的边插入与查重。
每次计算只加载两个分区到内存,称为一个 superstep,并在这两个分区之间进行操作。
预处理还生成三类元数据:
1.Degree file(度文件)
每个分区都有一个度文件,记录分区内每个顶点的入度和出度。
用途:提前知道每个顶点的边数,便于分配存储空间(避免边数组频繁扩展和复制)。
2.VIT(顶点区间表)
把所有顶点划分为若干区间,每个区间对应一个分区。VIT 记录这些区间的上下界。
用途:快速定位一个顶点属于哪个分区,以及在重分区时更新区间划分。
3.DDM(目标分布映射)
对于每个分区p,记录它的边指向其他分区 q 的比例。本质上是一个矩阵:行表示源分区p,列表示目标分区 q,单元格的值 = 从 p 指向 q 的边占比(百分比)。
用途:调度算法会根据DDM 来决定优先加载哪些分区(因为匹配边的机会更多)。还能用来判断是否还有新的边需要生成,从而决定分析是否可以终止。
E-P
Graspan 的核心计算模型:边对中心计算(Edge-Pair Centric Computation)
这一模型的限制是文法右部最多只能有两个符号。分析过程被组织成一系列supersteps。
每次supersteps:
1.加载两个分区(从磁盘到内存);
2.在这两个分区的边表中做合并操作;
3.根据文法规则产生新的边;
4.如果分区过大,则触发 repartition。
终止条件:没有新的边可以生成时,分析结束。
每个顶点的边表用两个数组表示:
**Oᵥ (Old edges):**已经处理过的边;
**Dᵥ (Delta edges):**当前迭代中新发现的边。
这样可以避免重复工作,只需要处理与新边相关的组合
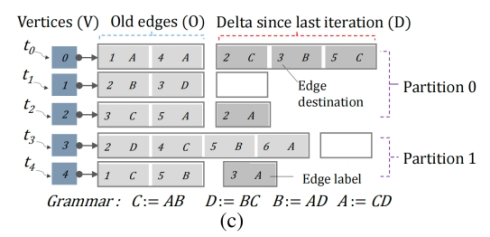
初始化:Oᵥ = ∅, Dᵥ = 原始边。
迭代:
- Oᵥ + Dᵤ → 新边
- Dᵥ + (Oᵤ ∪ Dᵤ) → 新边
- 更新:Oᵥ ← Oᵥ ∪ Dᵥ, Dᵥ ← 新边 – Oᵥ
收敛:直到所有Dᵥ = ∅ → 没有新边产生。


关键点
边对匹配:核心就是检查(L₁, L₂) 是否符合文法规则。
批量处理:用归并排序合并多个有序边表,比逐条扫描快很多。
在线去重:避免重复边导致无限循环或冗余计算。
增量更新:只处理新边Dᵥ,大幅减少不必要的重复计算。
可以把这个算法理解成:每个顶点维护两份“通讯录”:一份是“老朋友 (Oᵥ)”,一份是“新认识的人 (Dᵥ)”。每次迭代时,老朋友帮你介绍他们的新朋友,新朋友帮你介绍所有朋友→ 不断扩展认识的人。等到没有新朋友了,朋友圈就稳定了。
如果允许重复:算法可能永远不收敛(不断生成相同边)。或者即使能收敛,也会在时间和空间上造成巨大冗余(存储大量重复边,做很多无用计算)。
如果用一种很直接传统的方法,在生成新边 v –K–> x 之前,再扫描一次 v 的出边,检查是否已经存在相同的边。每生成一条新边,都要额外做一次查重扫描。在大规模图分析(数十亿条边)中,这样的代价非常高。
离线去重的替代方案:可以等分区写回磁盘时再统一去重,从而省掉在线检查的成本。风险:如果完全不做在线去重,可能导致算法不断把同一条边当作“新边”反复加入,这样主循环(Line 6)会一直认为有新工作,导致无法终止。
Graspan的算法实现了快速边添加与在线重复检测,而且是算法自带的“副产品”:
由于所有输入列表均已预排序,MATCHANDMERGESORTEDARRAYS可通过以下方式高效实现:在输入列表切片元素中反复查找最小值(采用O(log|V|)时间复杂度的最小堆算法),并将其复制到输出数组。该算法整体具有O(|E|log|V|)的时间复杂度,比逐个扫描边(O(|E|²))更高效,因为|V|远小于|E|。此外,在合并过程中可自动完成边去重——若多个元素具有相同最小值,仅将其中一个复制到输出数组。在复制前会执行标签匹配——若边的标签不合法,则不会被复制到输出中。
Postprocessing
- 通过调度器基于DDM 选择需要的分区对,并根据 delta 值判断是否还需要继续迭代。
- 终止条件:当所有分区对的delta 为 0 时,即不再产生新边,算法结束。
- 提供API 输出分析结果。
当某个分区的规模超过阈值(例如某个参数)时,就会触发重新分区。由于边列表已排序,Graspan能轻松对过大的分区进行重新划分。该系统会将原始顶点区间拆分为两个较小区间,边结构会自动重组。其目标是使两个小顶点区间拥有相近数量的边,从而确保新生成的分区规模相当。此时需用新区间信息更新顶点区间表(VIT)。若在superstep运算过程中新增过多边且已加载分区大小接近内存容量,也会在superstep中期触发重新分区。
当新的superstep阶段开始时,调度器会选择两个新分区加入运算。由于前一个superstep阶段已完成计算的分区可能被再次选中,Graspan系统会延迟将分区写回磁盘的操作,直至调度器完成新分区的选择。若被选中的分区已驻留内存,则可显著减少磁盘I/O操作的开销。
调度算法的两个目标
1.最大化潜在可匹配的边对数量即每次选择的分区对(p, q),希望它们之间能产生尽量多的新边。
2.尽量复用内存中的分区因为从磁盘加载分区很耗时,如果某个分区已经在内存里,就优先选择它和其他分区配对。
- 使用DDM,DDM 记录不同分区之间的边分布比例。比如:从分区 p 到 q 的边占 p 总边数的百分比。这个比例反映了 p 和 q 之间可能的匹配机会。
- 引入变化率δ(p, q):单纯用DDM 的静态百分比,不足以反映“最近是否还有新变化”。所以,Graspan 在每个 DDM 单元格中额外记录一个 变化率 δ(p, q)。δ(p, q) = 自上次加载p和q以来,p→q 的边数比例变化。如果p和q从未一起加载过,δ(p, q) 就等于完整比例。
- 调度策略:选择一对分区(p, q),使得δ(p, q) + δ(q, p)最大。如果有多个分区对得分相近(在用户设定范围内),就选包含已在内存中的分区的那一对。这样减少磁盘I/O 开销。
- 终止条件:如果某对分区(p, q) 的δ(p, q) + δ(q, p) = 0,说明这两个分区之间不可能再产生新边,就不必再对它们一起加载。当DDM中所有单元格的δ都为 0 → 没有新的边可生成 → 分析结束。

