YOLOv5的使用与训练
虚拟环境终端下载YOLOv5并下载相关依赖
git clone https://github.com/ultralytics/yolov5 # clonecd yolov5pip install -r requirements.txt # install
使用
使用方法1
可以在yolov5下自己创建一个xxx.py文件:
import torch |
使用python xxx.py运行该文件,可以使用现成的训练好的yolov5s模型进行目标检测。
使用方法2
也可以在终端输入python detect.py --weights yolov5s.pt --source xxxxxx进行检测。
例如python detect.py --weights yolov5s.pt --source 0可以实现摄像头实时目标检测。

或例如:python detect.py --weights yolov5s.pt --source img.jpg
(img.jpg对应的是位于yolov5文件夹下的名称为img.jpg的图像文件)
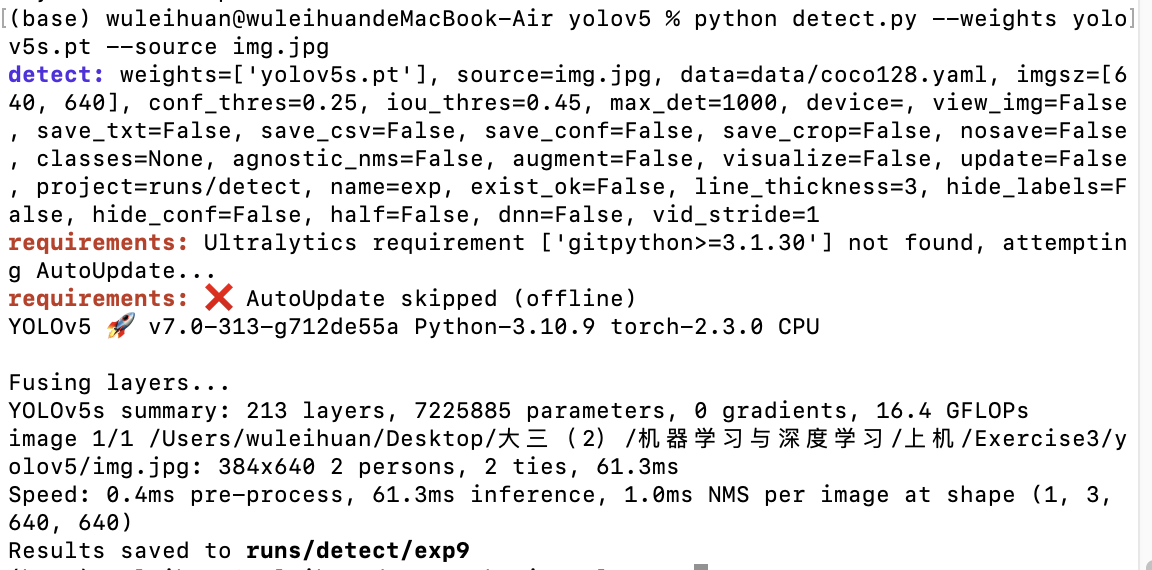
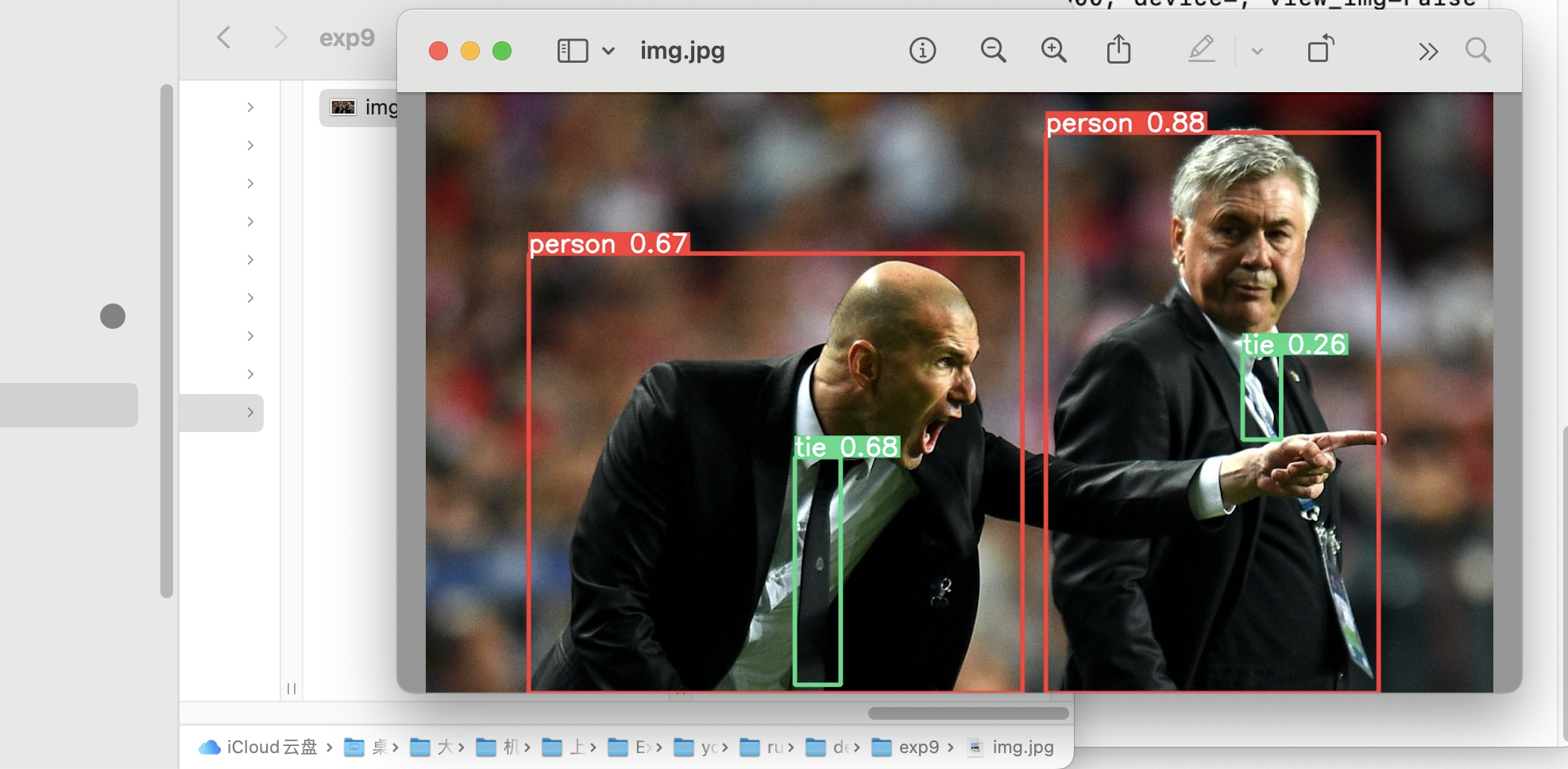
根据输出提示可以去yolov5/runs/detect/…下查看检测结果:
部署
将YOLOv5部署到web端(flask+js),此处省略代码,全部放在项目里了。
部署项目的app.py代码里有个地方要注意修改一下:
#定义新路由,显示图片 |
这里img_path有可能要改,比如window系统下可能是:
img_path = 'runs\\detect\\exp\\' + str(filename)
但macOS是:
img_path = 'runs/detect/exp/' + str(filename)
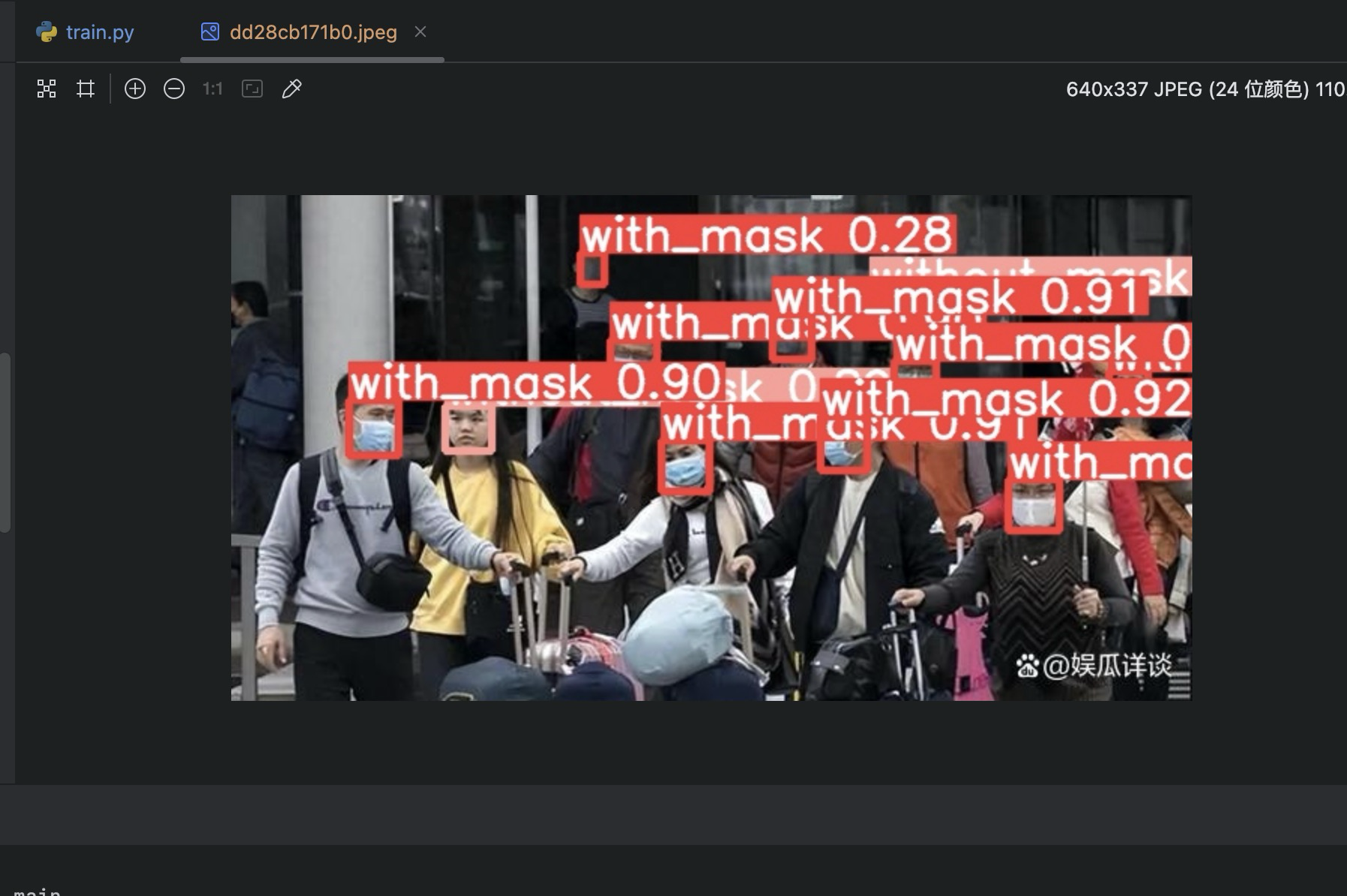
训练自己的模型(口罩数据集)CPU版
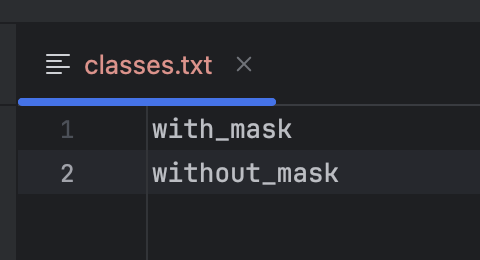
创建一个classes.txt文件(位置根据自己的习惯,记住路径就行):
再创建一个xml_to_txt.py文件:
import os |
运行这个文件⬆️,然后在转换后的 TXT 文件目录里找到转换好的txt文件。
在yolov5/data文件夹下新建如下文件夹:
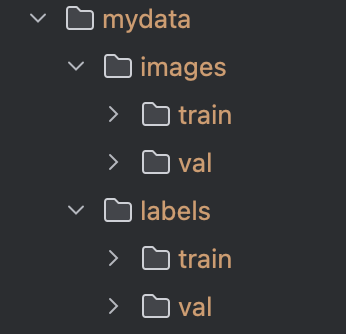
自己划分一下数据集,我把maksssksksss0-maksssksksss600当训练集,其他的当验证集了。
把训练集的png文件复制到yolov5/data/mydata/images/train文件夹里,txt文件(刚刚转换得到的)放到yolov5/data/mydata/labels/train文件里,同理,验证集的png文件放yolov5/data/mydata/images/val里,txt文件放yolov5/data/mydata/labels/val里:
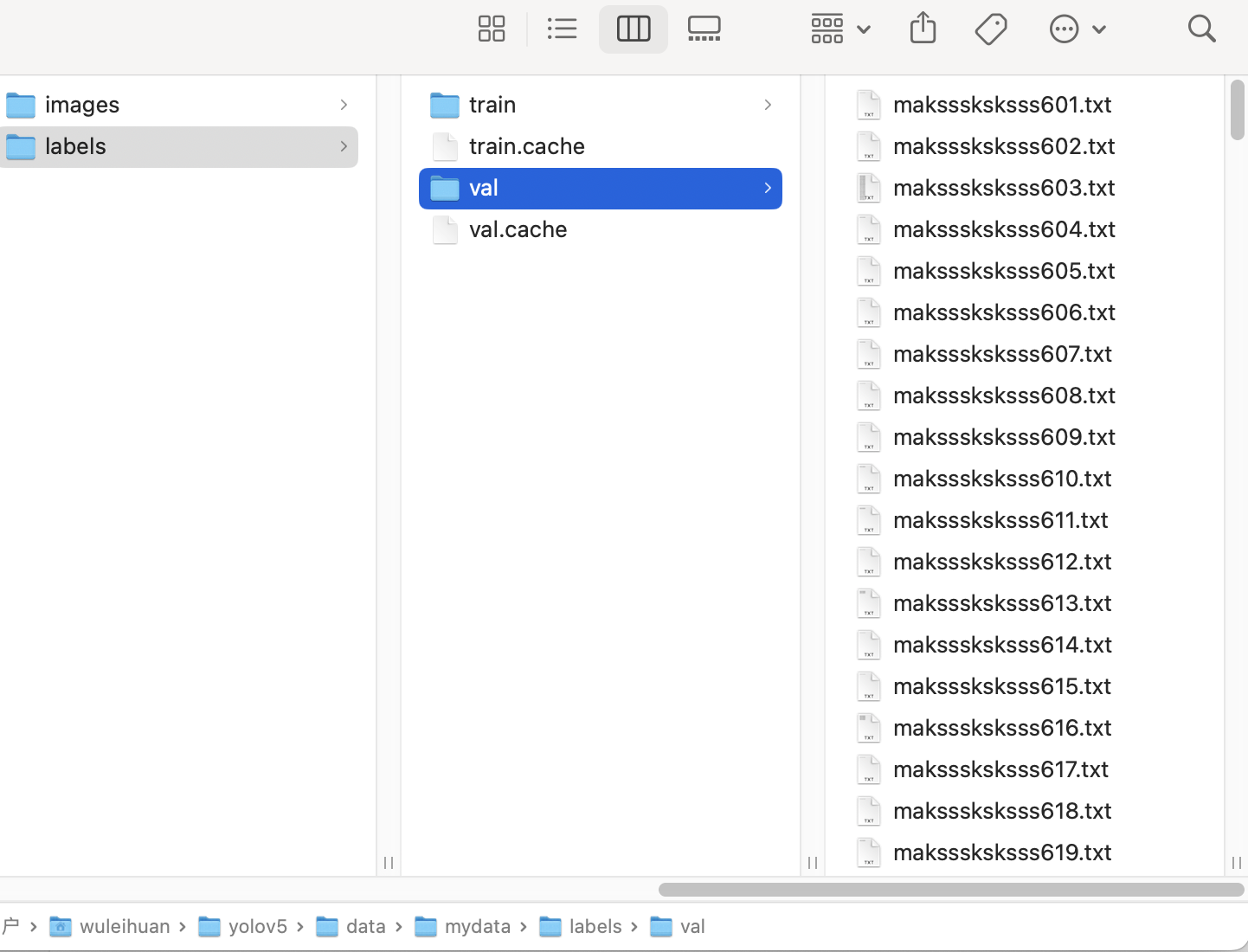
(cache文件是后面过程中出现的,不用管)
在yolov5/data文件夹下新建mydata.yaml(path改成自己的):
path: /Users/wuleihuan/yolov5/data/mydata |
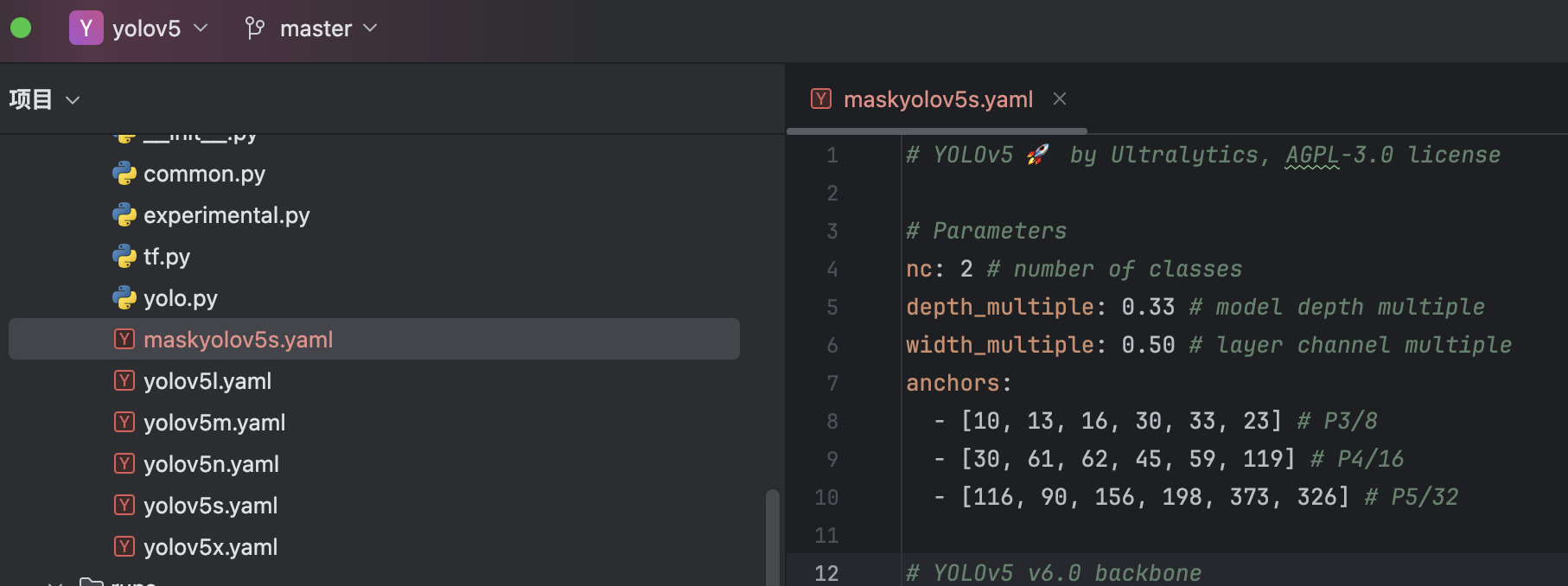
选择yolov5文件夹里的yolov5s.yaml文件复制一份,就放在yolov5目录下,命名为maskyolov5s.yaml(命名可以再规范一点,不要学我乱来),并修改了里面模型的nc(类别参数)为2:
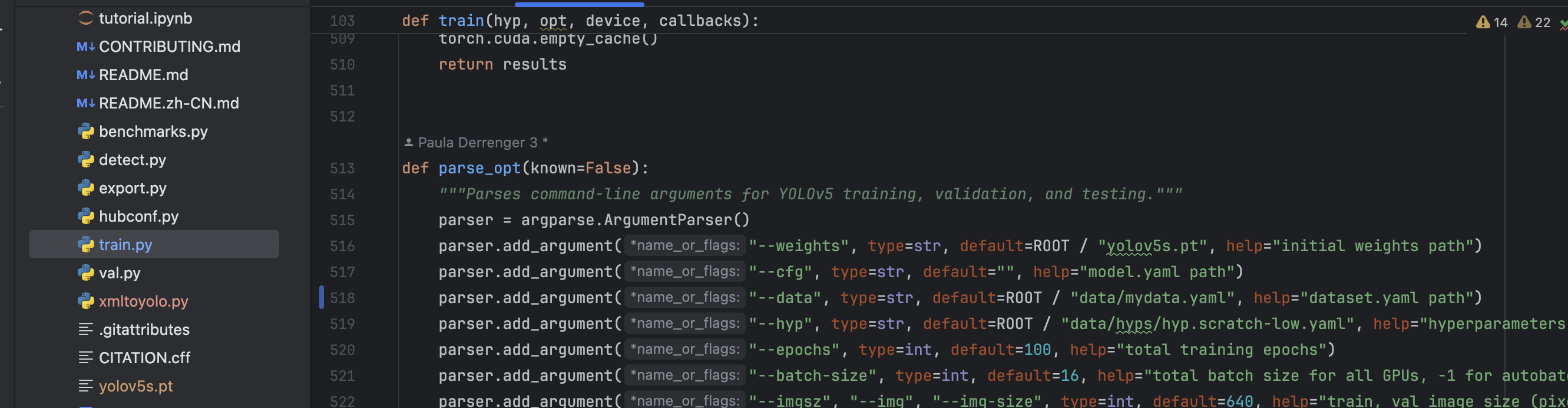
修改train.py文件,改成这样:
parser.add_argument("--data", type=str, default=ROOT / "data/mydata.yaml", help="dataset.yaml path")
然后在终端里输入:
python train.py --data data/mydata.yaml --weights yolov5s.pt --epoch 100 --batch-size 32 --cfg models/maskyolov5s.yaml
注意一下–epoch 100,如果只是想尽快看看训练效果,这个100可以改成小一点的数字,不然很慢。
跑完之后:

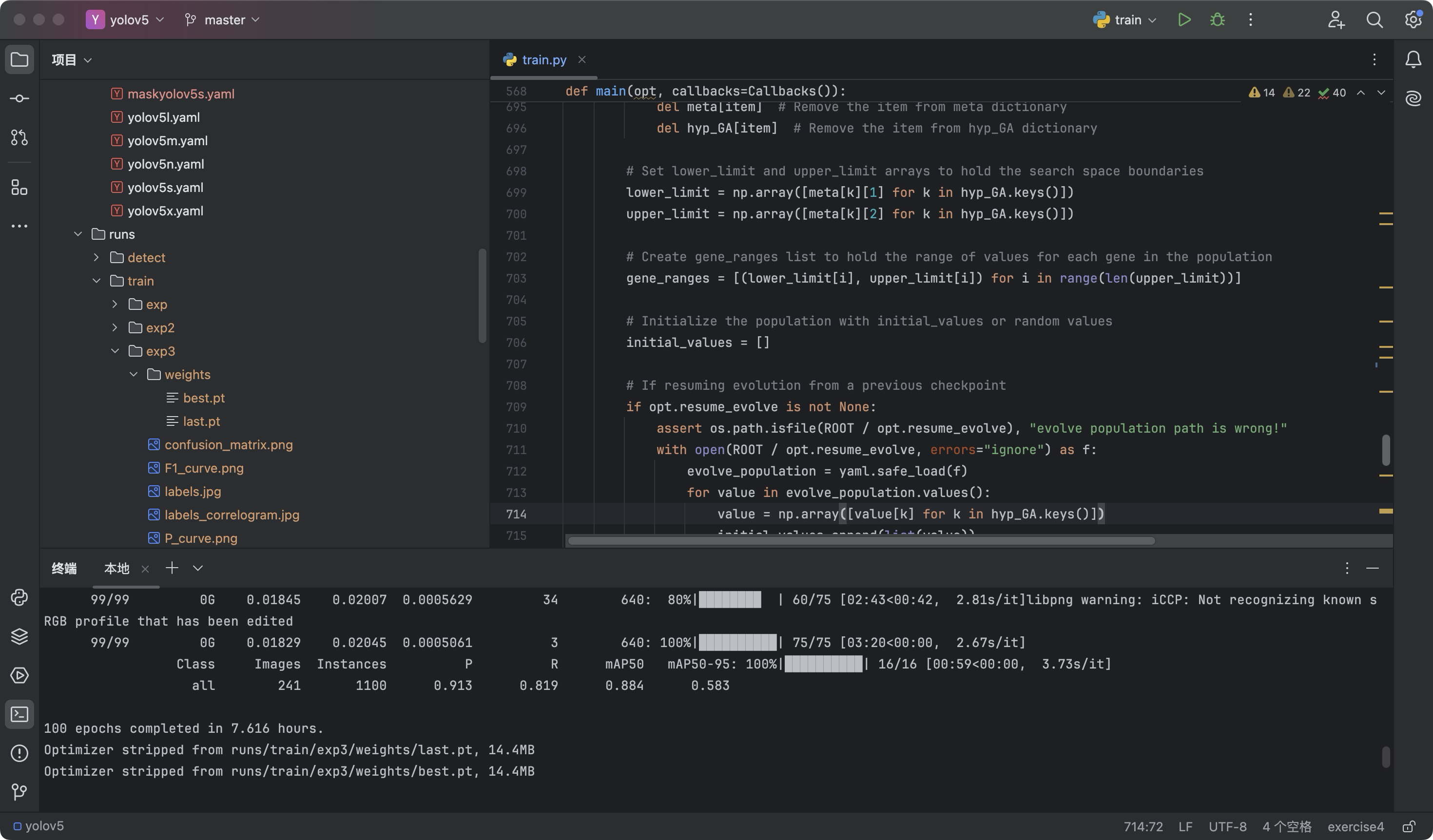
在终端输入如下命令
python detect.py --weights runs/train/exp3/weights/best.pt --source 0
可以实现摄像头实时检测了

同理,用 python detect.py --weights runs/train/exp3/weights/best.pt --source xxx.img 之类的也可以检测图片: